Bug #4138

`rbd ls` produce too much IOPS on Ceph
| Status: | Closed | Start date: | 11/05/2015 | |
|---|---|---|---|---|
| Priority: | Normal | Due date: | ||
| Assignee: |  Javi Fontan Javi Fontan | % Done: | 0% | |
| Category: | Drivers - Monitor | |||
| Target version: | Release 5.0 | |||
| Resolution: | fixed | Pull request: | 75 | |
| Affected Versions: | Development, OpenNebula 4.14 |
Description
Hello,
After upgrading our OpenNebula instance to 4.14, we noticed lots of more read IOPS (~ x10) on Ceph side. VM disks monitoring and `rbd ls` seems to be the cause.
Even if `rbd ls` calls are cached locally, we think it produces too much read IOPS for just monitoring purpose. I've wrote an alternative which uses `rbd info` instead of `rbd ls` [1].
[1] https://github.com/OpenNebula/one/pull/75
---
Pierre-Alain RIVIERE
Ippon Hosting
iops.png - I (58.7 KB)
{kind=link}
iops-mon.PNG - Ceph IOPs after decreasing monitoring intervall (96.3 KB)
{kind=link}
patch_opennebula_kvm_poll.txt  - add this class to /var/lib/one/remotes/vmm/kvm/poll
(3.56 KB)
- add this class to /var/lib/one/remotes/vmm/kvm/poll
(3.56 KB)
Associated revisions
bug #4138: do not use rbd ls -l deleting ceph volumes
bug #4138: do not use rbd ls -l deleting ceph volumes
(cherry picked from commit f0c137f8f2570b08d5f3e3f40928de19f81c6bd9)
bug 4138: do not get ceph disk info in vm poll
Space reported by ceph is the same OpenNebula has for the
full disk. Does not add any extra information.
bug #4138: Rework top parent search without rbd ls -l
History
#1
 Updated by Pierre-Alain RIVIERE over 5 years ago
Updated by Pierre-Alain RIVIERE over 5 years ago
- File iops.png added
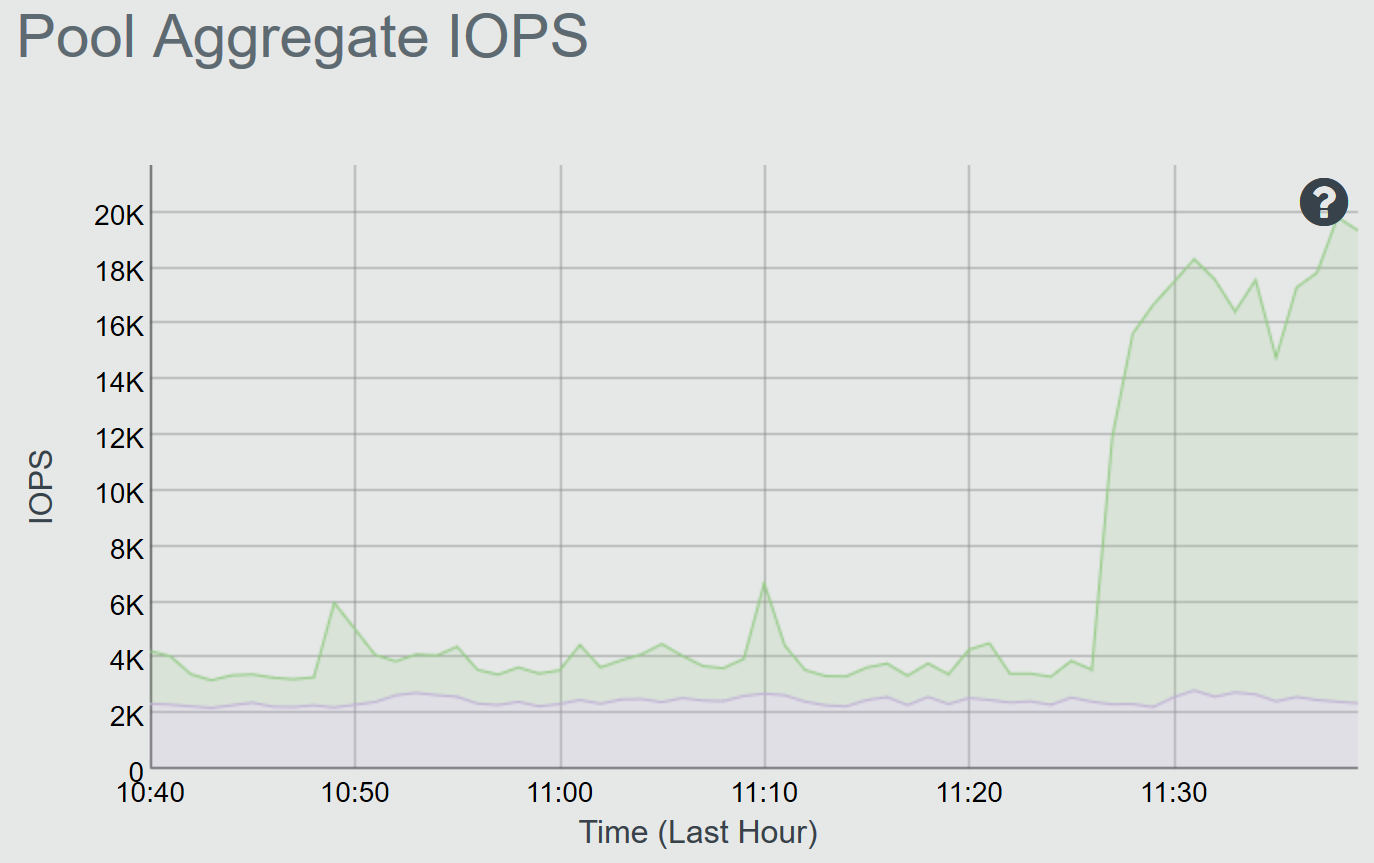
I've attached the "Pool Aggregate IOPS" graph from Calamari.
- 31 oct -> 02 nov : OpenNebula 4.12, monitoring interval 60s
- 03 nov : OpenNebula 4.14, monitoring interval 60s
- 04 nov -> 05 nov : OpenNebula 4.14, monitoring interval 5min
- 06 nov : OpenNebula 4.14, monitoring interval 60s and modifications from pull request 75#2
 Updated by Ruben S. Montero over 5 years ago
Updated by Ruben S. Montero over 5 years ago
- Target version set to Release 4.14.2
Thanks! planning this for next maintenance release
#3
Updated by Ruben S. Montero over 5 years ago
- Target version changed from Release 4.14.2 to Release 5.0
#4
 Updated by Tobias Fischer over 5 years ago
Updated by Tobias Fischer over 5 years ago
Hello,
we could observe the same as Pierre-Alain. As soon as we block the monitoring the read IOPS drop noticeably. We tried the alternative from Pierre-Alain but could not see any improvements.
Also we think that calling rbd ls on all monitored hosts at the same time (and so often) could be the cause of the high load.
Here are some proposals:
- monitor ceph datastore only from one Host - "OpenNebula Ceph Frontend" could be a good choice
- separate ceph monitoring cycle from normal host monitoring cycle - a longer timespan (or a kind of cache) should be enough for monitoring the size of images / datastore
@Pierre-Alain: Did your alternative you posted resolve the problem?
Thanks!
Best, Tobias
#5
Updated by Ruben S. Montero over 5 years ago
- Status changed from Pending to Closed
- Resolution set to fixed
Hi Tobias + Pierre-Alain
We have tuned the monitoring process for system shared datastores, to only monitor them once from one node, and not through all the hosts (issue #3987, http://dev.opennebula.org/projects/opennebula/repository/revisions/ee89a2185a21fde16add402b799c4a6c5266c735)
Cheers
Will close this for now, and reopen if the problem is observed with the new monitoring strategy
#6
Updated by Tobias Fischer over 5 years ago
- File iops-mon.PNG added
Hi Ruben,
that sounds great :-) it will be included in v5, right?
Here just for reference: see attached a screenshot of the IOPs after decreasing the monitoring intervall from 1800 to 120
Cheers,
Tobias
#7
Updated by Ruben S. Montero over 5 years ago
Hi,
THANKS for the update. The change is ready for 5.0, unfortunately it is not straightforward to back-port it to 4.14. So your solution is the proposed work-around for anybody in 4.14.
Cheers
Ruben
#8
 Updated by Esteban Freire Garcia over 5 years ago
Updated by Esteban Freire Garcia over 5 years ago
Hi Ruben,
Sorry, I am not sure which is the work-around proposed to solve this issue after reading all the comments.
Could you please indicate me what I need to do to solve this issue?
Thanks in advance,
Esteban
#9
Updated by Ruben S. Montero over 5 years ago
Hi Esteban,
AFAIK, increasing the monitor time could help (MONITORING_INTERVAL, in oned.conf, that will also increase the monitor time for other objects.) You can also easily perform 1 of every 10 monitor requests from the monitor script for example....
#10
Updated by Tobias Fischer over 5 years ago
Hi Ruben,
thanks for the update. Can you please explain how to apply your proposed workaroud?
"You can also easily perform 1 of every 10 monitor requests from the monitor script for example...."
Is there a time schedule for the v5 release?
Thank you!
Best,
Tobi
#11
Updated by Ruben S. Montero over 5 years ago
Hi
There is no strict deadline right now, we are aiming at some point in mid March or April.
#12
Updated by Esteban Freire Garcia over 5 years ago
Hi Ruben
Thanks a lot for you answer :)
Could you please indicate me which is the monitor script to which you are referring? and how do I apply to perform 1 of every 10 monitor requests from the monitor script?
Thanks in advance and sorry for the delay in answering you,
Esteban
#13
Updated by Tobias Fischer over 5 years ago
Hi,
we made a little workaround for this problem:
we expanded remotes/vmm/kvm/poll script with two new classes so that we can cache the results of the rbd commands into text files that are updated only once per day.
this reduced the load remarkably.
if someone is interested in the code i'm glad to help
Best,
Tobi
#14
Updated by Esteban Freire Garcia over 5 years ago
Hi Tobi,
Thank you very much for your answer. I am interested on your code, could you put your code here, please?
Also, I would appreciate if OpenNebula team could verify this workaround or put one available here.
We are going to update to 4.14.2 on production next week and I don't want to find surprises :)
Thanks in advance,
Esteban
#15
Updated by Esteban Freire Garcia over 5 years ago
Hi,
We upgraded yesterday to 4.14.2 on production and we are seeing the same issues :(
We would appreciate to have a workaround to solve this issue as soon as possible.
Thanks in advance,
Esteban
#16
Updated by Esteban Freire Garcia over 5 years ago
I forgot to say that we have already increased the time on MONITORING_INTERVAL, in oned.conf.
Thanks in advance,
Esteban
#17
Updated by Tobias Fischer over 5 years ago
- File patch_opennebula_kvm_poll.txt added
Hello,
here is the changes we introduced as workaround:
we created a new class in the poll script /var/lib/one/remotes/vmm/kvm/poll.
the goal is to cache the results of the rbd "ls" and "info" commands into files and feed the poll script from the files instead of live rbd commands results. the results are updated once per day (can be changed in code)
for the class see attached file.
furthermore we replaced the two commands in the poll script with the commands of the new class:
def self.rbd_info(pool, image, auth=nil)
#`rbd #{auth} info -p #{pool} --image #{image} --format xml`
Rbdcache.info(auth, pool, image)
end
def self.rbd_ls(pool, auth = nil)
@@rbd_ls ||= {}
if @rbd_ls[pool].nil?
#@rbd_ls[pool] = `rbd #{auth} ls -p #{pool} --format xml`
@@rbd_ls[pool] = Rbdcache.ls(auth, pool)
endDon't forget to sync all hosts with changed script.
If there are any questions feel free to ask
Best,
Tobi
#18 Updated by Anonymous over 5 years ago
We can confirm that initial pull request solves the issue.
#19
Updated by Ruben S. Montero over 5 years ago
- Status changed from Closed to Pending
Hi,
Brief update. We have been experimenting problems with the proposed patch when there are > 200 images in a pool. In that case the patch reduces the time from ~15min to ~5min. We will do two things:
1.- use the catching approach for info
2.- Part of the rbd ls commands are still being executed at the hypervisors. We want to move that part also to the datastore monitorization (which is now performed at one place).
Thanks
Ruben
#20
 Updated by Javi Fontan about 5 years ago
Updated by Javi Fontan about 5 years ago
- Status changed from Pending to Closed
- Assignee set to Javi Fontan
VMM poll no longer gets Ceph disk information. Ceph does not report occupied space but maximum size.